Key Takeaways
- We need to understand MySQL design so that we can work with it, and not against it.
- Everything in InnoDB is an index. The primary key is used for the clustered index, so we must choose it with care.
- Monitoring is an absolute must in performance tuning.
MySQL’s Logical Architecture
MySQL is very different from other database servers, and its architectural characteristics make it useful for a wide range of purposes. MySQL is not perfect, but it is flexible enough to work well in very demanding environments, such as web applications, data warehouses, content indexing, highly available redundant systems, online transaction processing (OLTP), and much more.
To get the most from MySQL, we need to understand its design so that we can work with it, and not against it.
MySQL’s most unusual and important feature is its storage-engine architecture, whose design separates query processing and other server tasks from data storage and retrieval.
Query Execution Basics
If you need to get high performance from your MySQL server, one of the best ways to invest your time is in learning how MySQL optimizes and executes queries. Once you understand this, much of query optimization is a matter of reasoning from principles, and query optimization becomes a very logical process.
Here is the process MySQL follows when we send a query to the server.
- The client sends the SQL statement to the server.
- The server checks the query cache. If there’s a hit, it returns the stored result from the cache; otherwise, it passes the SQL statement to the next step.
- The server parses, preprocesses, and optimizes the SQL into a query execution plan.
- The query execution engine executes the plan by making calls to the storage engine API.
- The server sends the result to the client.
Each step takes time and may itself be a complex operation consisting of several subparts, which we discuss in the following sections.
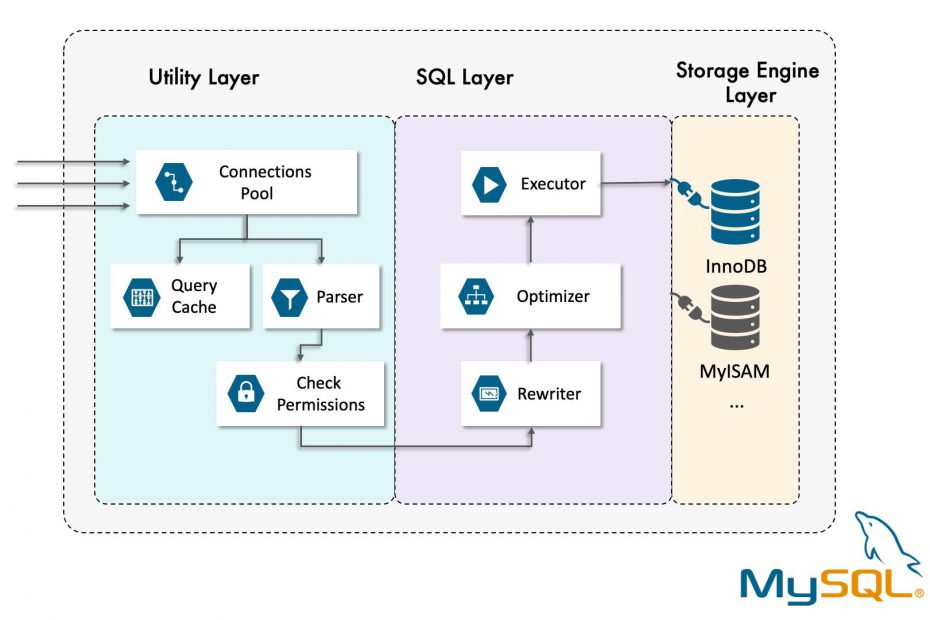
MySQL Server can be divided into 3 layers.
Utility Layer
The first layer contains the services that aren’t unique to MySQL. Client-server architecture and most of the network-based tools need these services. Connection handling, authentication, security, and so forth.
The MySQL Cient/Server Protocol
This CLIENT/SERVER protocol, makes MySQL communication simple and fast, but it limits it in some ways too. For one thing, it means there’s no flow control; once one side sends a message, the other side must fetch the entire message before responding. When the server responds, the client has to receive the entire result set. This is why LIMIT clauses are so important.
Now, if we are using libraries to connect to MySQL, then we should be aware that the default behaviour for most libraries is to fetch the whole result and buffer it in memory. This is important because until all the rows have been fetched, the MySQL server will not release the locks and other resources required by the query. The query will be in the “Sending data” state. When the client library fetches the results all at once, it reduces the amount of work the server needs to do: the server can finish and clean up the query as quickly as possible.
Most client libraries let you treat the result set as though you’re fetching it from the server, although in fact, you’re just fetching it from the buffer in the library’s memory.
This works fine most of the time, but it’s not a good idea for huge result sets that might take a long time to fetch and use a lot of memory. You can use less memory, and start working on the result sooner, if you instruct the library not to buffer the result. The downside is that the locks and other resources on the server will remain open while your application is interacting with the library.
The Query Cache
Before even parsing the query, though, the server consults the query cache, which can store only SELECT statements, along with their result sets. If anyone issues a query that’s identical to one already in the cache, the server doesn’t need to parse, optimize, or execute the query at all—it can simply pass back the stored result set.
SQL Layer
The second layer is where things get interesting. Much of MySQL’s brains are here, including the code for query analysis, optimization, caching, and all the built-in functions (e.g., dates, times, math, and encryption). Any functionality provided across storage engines lives at this level: stored procedures, triggers, and views, for example.
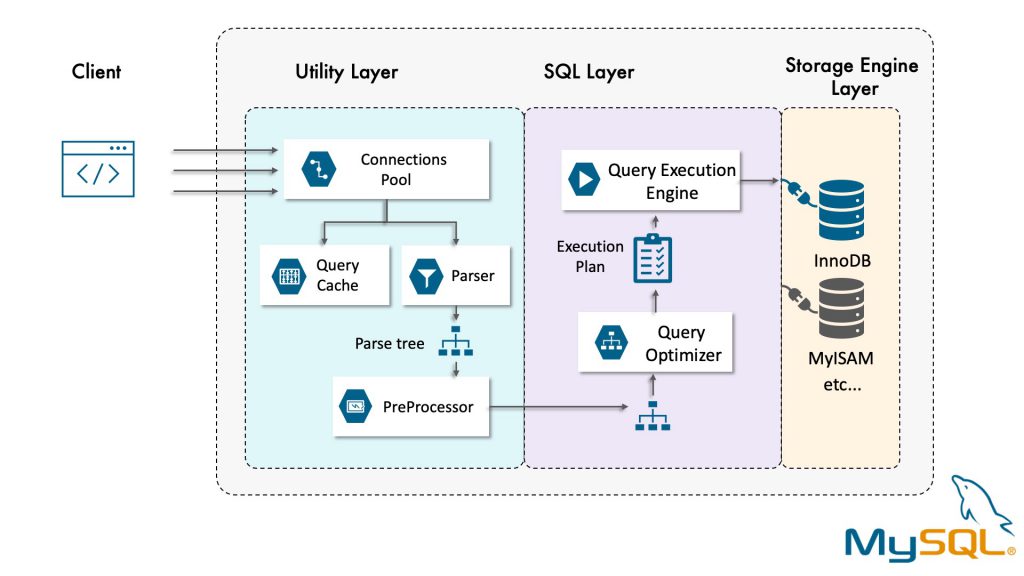
The next step in the query lifecycle turns a SQL query into an execution plan for the query execution engine. It has several substeps: parsing, preprocessing, and optimization.
The goal of this section is not trying to document the MySQL internals, but simply to understand how MySQL executes queries so that we can write better ones.
The parser and the preprocessor
To begin, MySQL’s parser breaks the query into tokens and builds a “parse tree” from them. The parser uses MySQL’s SQL grammar to interpret and validate the query. For example, for mistakes such as quoted strings that aren’t terminated, or checking that tables and columns exist.
Next, the preprocessor checks privileges. This is normally very fast unless your server has large numbers of privileges.
The query optimizer
The parse tree is now valid and ready for the optimizer to turn it into a query execution plan. A query can often be executed many different ways and produce the same result. The optimizer’s job is to find the best option.
MySQL uses a cost-based optimizer, which means it tries to predict the cost of various execution plans and choose the least expensive.
It bases the estimate on statistics: the number of pages per table or index, the cardinality (number of distinct values) of the indexes, the length of the rows and keys, and the key distribution. The optimizer does not include the effects of any type of caching in its estimates—it assumes every read will result in a disk I/O operation.
The optimizer might not always choose the best plan, for many reasons:
- The statistics could be wrong. The server relies on storage engines to provide statistics, and they can range from exactly correct to wildly inaccurate. For example, the InnoDB storage engine doesn’t maintain accurate statistics about the number of rows in a table because of its MVCC architecture.
- The cost metric is not exactly equivalent to the true cost of running the query. It might be more or less expensive than MySQL’s approximation. For example when MySQL doesn’t understand which pages are in memory and which pages are on disk, so it doesn’t really know how much I/O the query will cause.
- You probably want the fastest execution time, but MySQL doesn’t really try to make queries fast; it tries to minimize their cost.
- The optimizer can’t always estimate every possible execution plan, so it might miss an optimal plan.
MySQL’s query optimizer can apply Static optimizations such as those independent of values, For example, constant values in a WHERE clause. They can be performed once and will always be valid, even when the query is re-executed.
In contrast, dynamic optimizations are based on context and can depend on many factors, such as which value is in a WHERE clause or how many rows are in an index. They must be reevaluated each time the query is executed. You can think of these as “runtime optimizations.”
MySQL knows how to do a lot of optimizations on its own such as Reordering joins, converting joins, Applying algebraic equivalence rules, COUNT(), MIN(), and MAX() optimizations, Subquery optimization, and so on.
Of course, as smart as the optimizer is, there are times when it doesn’t give the best result. Sometimes you might know something about the data that the optimizer doesn’t.
If you know the optimizer isn’t giving a good result, and you know why, you can help it. Some of the options are to add a hint to the query, rewrite the query, redesign your schema, or add indexes as we’ll see in future sections.
The query execution engine
The parsing and optimizing stage outputs a query execution plan, which MySQL’s query execution engine uses to process the query.
In contrast to the optimization stage, the execution stage is usually not all that complex: MySQL simply follows the instructions given in the query execution plan. Many of the operations in the plan invoke methods implemented by the storage engine interface, also known as the handler API.
Returning results to the client
The final step in executing a query is to reply to the client. Even queries that don’t return a result set still reply to the client connection with information about the query, such as how many rows it affected.
If the query is cacheable, MySQL will also place the results into the query cache at this stage.
Storage Engine Layer
The third layer contains the storage engines. They are responsible for storing and retrieving all data stored “in” MySQL. They are implemented as plugins which makes it relatively easy to implement different ways to handle data.
The main storage engine – and the only one that will be considered in this guide – is InnoDB which is fully transactional and has very good support for high-concurrency workloads.
An example of another storage engine is NDBCluster which is also transactional and is used as part of MySQL NDB Cluster.
The optimizer does not really care what storage engine a particular table uses, but the storage engine does affect how the server optimizes the query. The optimizer asks the storage engine about some of its capabilities and the cost of certain operations, and for statistics on the table data.
The storage engine may itself be complex. For InnoDB, it includes a buffer pool used to cache data and indexes, redo and undo logs, other buffers, as well as tablespace files. If the query returns rows, these are sent back from the storage engine through the SQL layer to the application.
Before even parsing the query, though, the server consults the query cache, which can store only SELECT statements, along with their result sets. If anyone issues a query that’s identical to one already in the cache, the server doesn’t need to parse, optimize, or execute the query at all—it can simply pass back the stored result set.
In query tuning, the most important steps are the optimizer and execution steps including the storage engine. Most of the information in this guide relates to these three parts either directly or indirectly.
The InnoDB Engine
InnoDB is a general-purpose storage engine that balances high reliability and high performance and it was designed for processing many short-lived transactions. You should use InnoDB for your tables unless you have a compelling need to use a different engine. If you want to study storage engines, it is also well worth your time to study InnoDB in depth to learn as much as you can about it, rather than studying all storage engines equally.
InnoDB tables are built on a clustered index and is the term used for how InnoDB organizes the data. The name comes from the fact that index values are clustered together. Everything in InnoDB is an index. The row data is in the leaf pages of a B-tree index.
The primary key is used for the clustered index. If you do not specify an explicit primary key, InnoDB will look for a unique index that does not allow NULL values. If that does not exist either, InnoDB will add a hidden 6-byte integer column using a global (for all InnoDB tables) auto-increment value to generate a unique value.
As a result, it provides very fast primary key lookups. However, secondary indexes (indexes that aren’t the primary key) contain the primary key columns, so if your primary key is large, other indexes will also be large. You should strive for a small primary key if you’ll have many indexes on a table.
The choice of primary key also has performance implications. These will be discussed in the section “Index Strategies” later in another section.
Sources of Information
If you take just one thing with you from following this section, then let it be that monitoring is critical to maintaining a healthy system. Everything about high performance should revolve around monitoring.
Your monitoring should use several sources of information. These include but are not limited to
- The Performance Schema – which includes information ranging from low-level mutexes to query and transaction metrics. This is the single most important source of information for query performance tuning. The sys schema provides a range of ready-made reports based on the Performance Schema, but they include filters, sorting, and formatting that make the reports easy to use.
USE performance_schema;
SHOW TABLES;
- The Information Schema – which includes schema information, InnoDB statistics, and more.
- SHOW statements – which, for example, include information from InnoDB with detailed engine statistics.
SHOW TABLE STATUS LIKE 'city' \G;
- The slow query log – which can record queries matching certain criteria such as taking longer than a predefined threshold, even after instance restarts.
- The EXPLAIN statement to return the query execution plan. This is an invaluable tool to investigate why a query is not performing well due to missing indexes, the query being written in a suboptimal way, or MySQL choosing a suboptimal way to execute the query. The EXPLAIN statement is mostly used in an ad hoc fashion when investigating a specific query.
- Operating system metrics such as disk utilization, memory usage, and network usage. Do not forget simple metrics such as the amount of free storage as running out of storage will cause an outage.
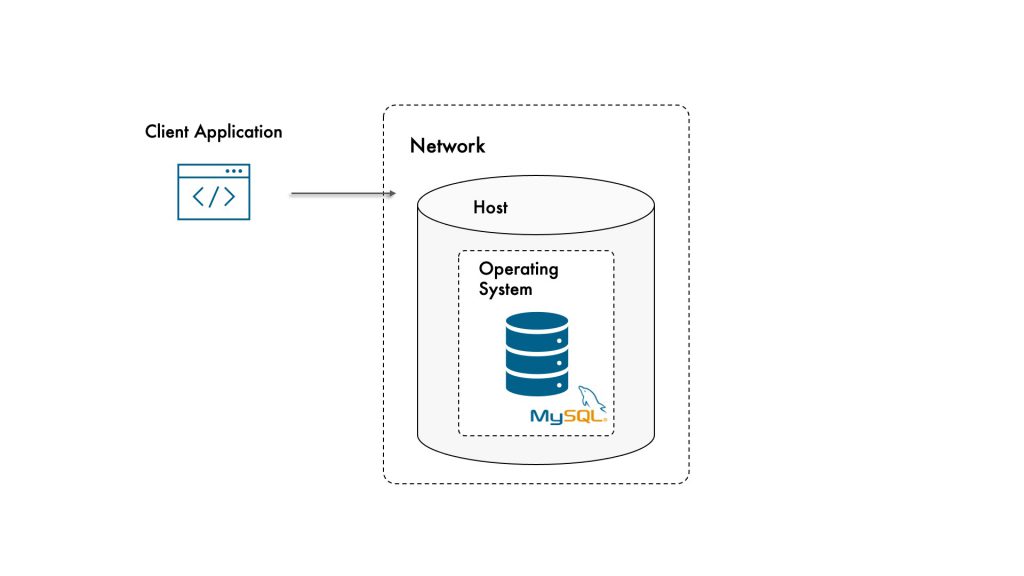
Consider the Whole Stack
When an application needs the result of the query or needs to store data in MySQL, it sends the request over the network to MySQL, and in order to execute the request, MySQL interacts with the operating system and uses host resources such as memory and disk. Once the result of the request is ready, it is communicated back to the application through the network.
Query Tuning Methodology
Performance tuning can be seen as a continuous process where an iterative approach is used to gradually improve performance over time.
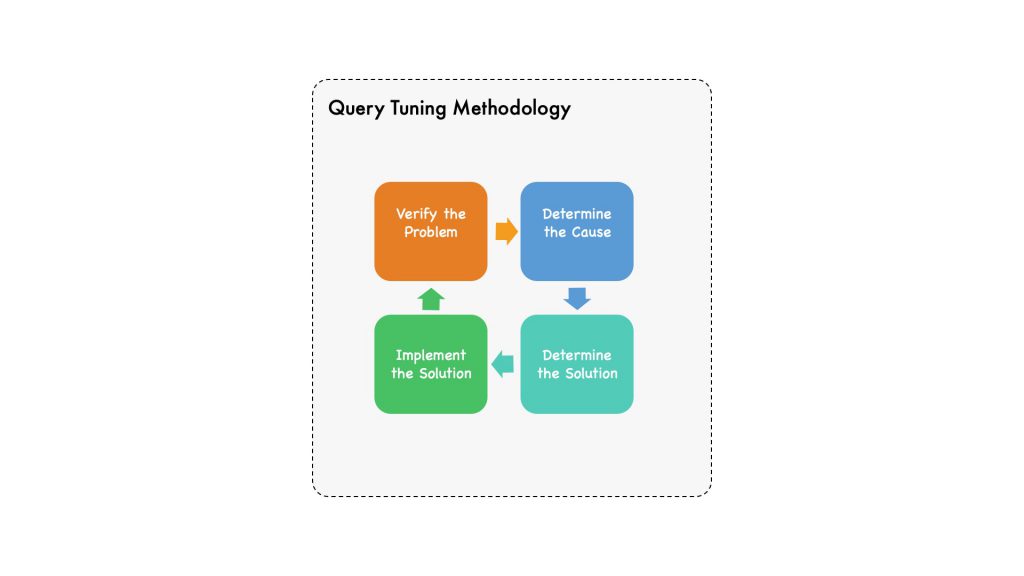
First, we should have a clear problem description. It is not enough to say “MySQL is slow”. A specific problem may be that “The query used to display user’s transactions takes five seconds” or that “MySQL can only sustain 5000 transactions per second.” The more specific we are, the better chance we have solving the problem.
The preparation work should also include collecting a baseline from our monitoring or running a data collection that illustrates the problem. Without the baseline, we may not be able to prove that we have solved the issue at the end of the troubleshooting.
Then we can work on determining the cause of the poor performance is. Here, we can be open-minded and consider the whole stack, so we don’t end up staring ourselves blind on one aspect that turns out not to have anything to do with the problem.
Finding the cause is often the hardest part of an investigation, but we’ll cover some good starting points and common causes in a later section.
And once the cause is clear, we can determine what we want to do to solve the problem.
The first step is to brainstorm possible solutions; second, you must choose which one to implement. It can happen that the solution we first chose does not work or have unacceptable side effects.
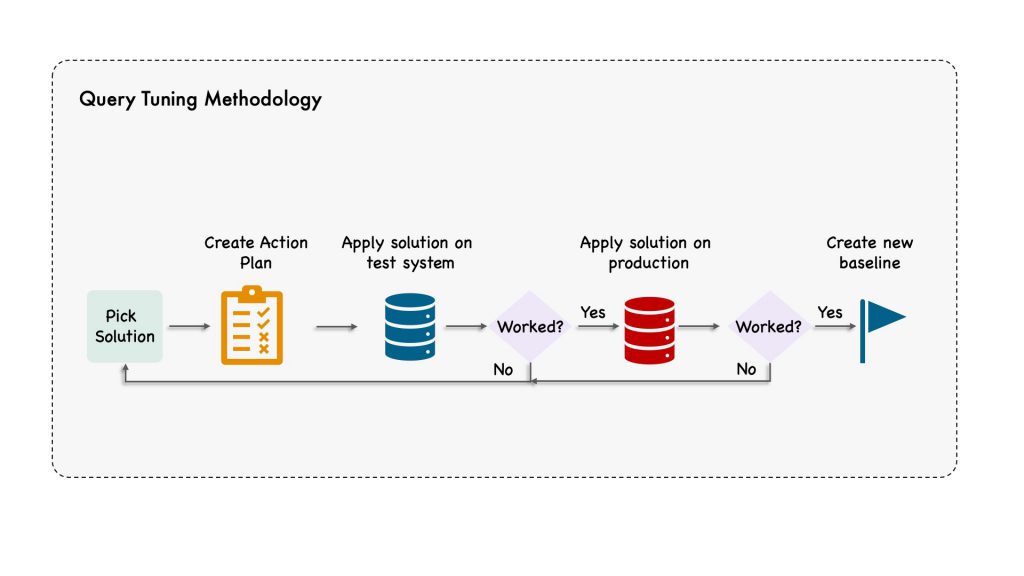
When we apply a solution we picked it’s important to create an action plan for it. Here it is important to be very specific, so we can ensure that the action plan we test is also the one we’ll end up applying to our production system.
We then need to test the action plan on a test system. It is important that it reflects production as closely as possible. The data we have on the test system must be representative of our production data. One way to achieve this is to copy the production data, optionally using data masking to avoid copying sensitive information such as personal details and credit card information out of our production system.
It is possible that for one reason or another, the solution does not completely work as expected on production. One possibility is that the index statistics that are random in nature were different, so an ANALYZE TABLE statement to update the index statistics was necessary when applying the solution to the production system.
If the solution works, you should collect a new baseline that you can use for future monitoring and optimizations.
We are then ready to start all over, either doing a second iteration to improve the performance further for the problem we have just been looking at, or we may need to work on a second problem.
Conclusions
MySQL has a layered architecture, with server-wide services and query execution on top and storage engines underneath.
The key takeaways are that you need to consider the whole stack from the end user to the low-level details of the host and operating system and monitoring is an absolute must in performance tuning. Executing a query includes several steps, of which the optimizer and execution steps are the most important and are ones that you will learn the most about in later sections.
Bibliography
- MySQL 8 Query Performance Tuning, Jesper Wisborg Krogh, Apress, March 2020
- High Performance MySQL, 3rd Edition, Baron Schwartz, Peter Zaitsev, Vadim Tkachenko, O’Reilly Media, Inc., March 2012