Key takeaways
- Opening a new PostgreSQL connection is a fairly expensive operation in terms of CPU used.
- Connection poolers keep some of those connections open all the time to reduce that overhead.
- There two main options to implement a connection pooler: at the database level and at the application level.
- When sizing a connection pool, you should have enough connections to use all of the available resources, but not more than that.
Basic idea
Establishing a connection to a database can be quite expensive. It implies network handshaking, authentication, and allocating server resources for each new session. Below are all steps that happen for every connection:
- Opening a connection to the database
- Authenticate user on the database
- Opening a TCP socket for reading/writing data
- Reading / writing data over the socket
- Closing the connection
- Closing the socket
Imagine a web application that connects to a database for each request from a user. Every request would actually send a query to the database and then disconnect. It could take some milliseconds, but when the number of requests is enormous, it can take a lot of time in total. If these requests are sent simultaneously, it can happen that too many connections are created and the database server is overloaded. Furthermore, each connection consumes resources from the server.
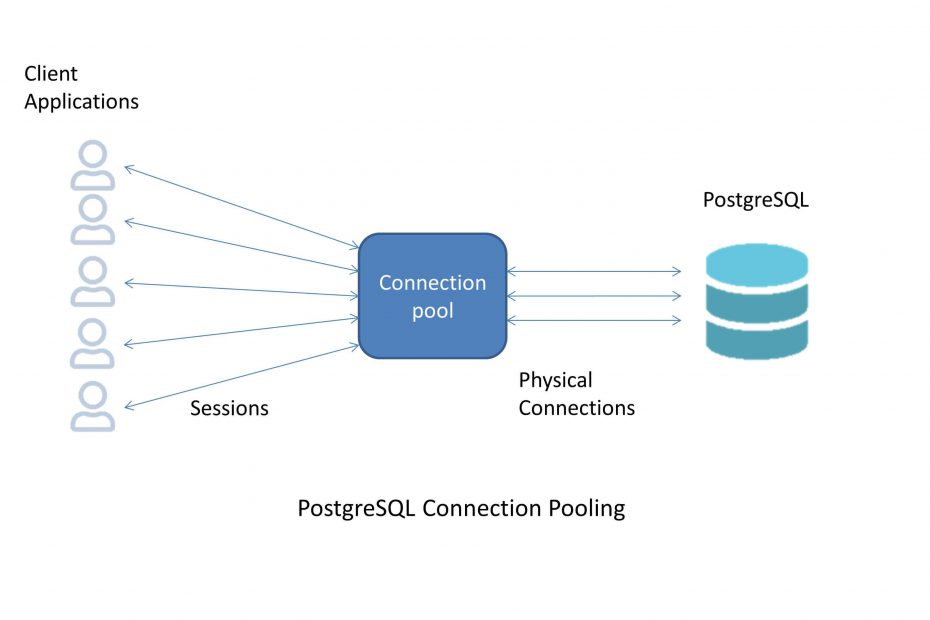
In web applications, it’s a common practice to create a fixed number of database connections in advance and then reuse them for different tasks. When there are more tasks than the number of connections, they should be blocked until there is a free connection. This is called connection pooling. There are two main benefits of using connection pooling. First, we have no time spent when connecting to the database as the connections are created in advance. Second, the number of connections is limited, which helps managing the server’s resources
Connection pooling in PostgreSQL
On PostgreSQL, the process of connecting to the database does not happen fast. Each connection requires starting a new backend process, which is an expensive operation. Then the authentication implementation is optimized for security and flexibility, rather than speed. The presumption is that users will run things for a long time compared to how long it takes to connect.
However, when dealing with web applications, we can reduce this overhead by using connection pooling. The connection pool sits between your application and the database. It makes a fixed number of connections to the database, typically under 100, and keeps them open all the time. As incoming requests come in, those connections in the pool are re-used. When clients disconnect, the connection pool manager just resets the session but keeps the connection in the pool in order to be ready to use for a new client.
Pool size
The fundamental idea behind sizing a connection pool is that you should have enough connections in order to use all of the available resources, but not more than that. The right size to saturate the server depends on the hardware, it usually depends on the number of CPU cores. Once you’ve moved beyond the point where the server is busy all the time, adding more connections will reduce efficiency. The server will be forced to switch between multiple tasks without doing any useful work.
Maximum database connections
It’s hard to predict how many pooled connections to the database are necessary to fully utilize the system but without overloading it. Many users report optimal connection counts to be between two and three times the number of cores on the system. A standard iterative technique is to start with 100 connections and then tune the number down from there if the server load seems too high.
The optimal count should probably be lower than you’d expect. You might think that your server needs lots of connections to handle a heavy load. But in reality, once you’ve saturated all of the CPUs on the server then if you try to execute more things simultaneously you will just decrease efficiency. Almost all of the time, you’ll be better off queuing the connections, and then they will be picked to be executed on a lightly loaded server without causing congestion.
If most of your connections spend a good part of their time IDLE (as shown by pg_stat_activity), you should probably reduce their number.
From a monitoring perspective, direct connection overhead will show up as a mix of user and kernel time which is spent. Therefore expect both times to reduce with a pooler in front of the database. If your system spends most of its time waiting for disk I/O instead, it’s unlikely that a connection pool will help you out. However, caching might help.
Options for connection pooling
There are really two major options when it comes to connection pooling and one that acts more like a hack.
- Standalone pooler
- Framework pooler
- Persistent connections
Standalone pooling
A standalone pooler can be much more configurable overall. It will let you specify how it works for Postgres sessions, transactions, or statements. There are mainly two options pgBouncer and pgpool-II.
pgBouncer
The PostgreSQL connection pooler with the highest proven performance in the field is pgBouncer, a project originating as part of the database scaling work done by Skype.
Designed to be nothing but a high-performance connection pooler, it excels at solving that particular problem of PostgreSQL connection management. pgBouncer runs as a single process without spawning a new process for each connection. The internal queue management for waiting connections is configurable so that it’s easy to avoid timeouts.
If you have hundreds or thousands of connections and you are out of CPU time then pgBouncer should be your first consideration as a way to reduce the amount of processor time being used.
When it comes to monitoring the pool itself, pgbouncer displays its internal information by a database interface. You can even send commands to the interface. Simply connect to the pgbouncer database on the port where pgBouncer is running. Using the standard psql tool, you can use the SHOW command to get a variety of information about the internal state of the pool. The console interface accepts commands like PAUSE and RESUME to control the operation of the pool.
Another feature of pgBouncer is that it can connect to multiple database servers running on different hosts. This allows a form of partitioning and therefore you can scale up. This means that your database model should allow splitting among many databases. Finally, you can simply move each database to its own host and merge them together using pgBouncer as the mediator.
pgpool-II
Its primary purpose is not just connection pooling, it also provides load balancing and replication capabilities. It even supports some parallel query setups. Queries are broken into pieces and spread across nodes. The primary purpose of pgpool is to handle multiple servers. It will serve as a proxy server between the clients and some databases.
As a connection pooler, there are a few limitations for pgpool-II setup. One is that each connection is set up with its own process. The memory overhead of this approach, with each process using a chunk of system RAM, can be significant. pgpool-II is not known for having powerful monitoring tools either.
But the main drawback of the program is its queuing model. Once you’ve gone beyond the number of connections that it can handle, additional ones are queued up at the operating system level. Each connection will wait for its network connection to be accepted. This can result in timeouts that depend on the network configuration. It’s a good idea to proactively monitor the “waiting for connection” time in your application and look for situations where it’s grown very large. Then you should correlate that with any timeouts that your program might run into.
Framework pooling
You may not need to use a database-level connection pooler based on the application you’re running. Some programming models include what are referred to as an application server, an idea that was popularized by Java. Well-known application servers for Java include Tomcat, JBoss, and others. The Java database access library, JDBC includes support for connection pooling. Popular connection pooling frameworks include:
- Apache Commons DBCP
- HikariCP
- C3PO
There are also connection poolers available for some other applications as well. It’s not an idea unique to Java application servers. If you have such an application-level pooling solution available, you should prefer it for two main reasons, beyond just reducing complexity. First, it’s probably going to be faster than passing through an additional layer of software just for pooling purposes. Second, monitoring of the pool is integrated into the application server already. However, you’ll still need to monitor the database underneath the pool.
Persistent connections
This approach intends to keep an initial connection active from the time it is initiated until it is dropped. It doesn’t fully hold the connection pooling features but it is good enough to provide some continuous connection.
We have a function, pg_pconnect(), which makes a connection persistent in PostgreSQL. Persistent connections are useful to reuse existing connections if any new connection is needed. One real use case for persistent connection is that we can use the same database connection during multiple page reloads on a web application. There are also some caveats about persistent connections. We need to take care of the lifecycle of persistent connections.
Conclusions
This section explains the difficulties you can encounter when large numbers of connections are made to the database at once. Connection pooling for PostgreSQL helps us reduce the number of resources required for connecting to the database and improves the speed of connectivity to the database.