Definitions
Reactive programming is a programming paradigm oriented toward data flows and the propagation of change: programming with asynchronous data streams.
Reactive programming can be seen from different angles:
- it replaces the well-known observer pattern, in particular, defined as listeners and callbacks.
- it’s a modular, composable approach to event-driven programming logic
- It brings order to the management of program state.
- it shifts thinking and can be viewed as a flow of data: the program is expressed as a reaction to its inputs
- it’s usually implemented as a software library
Context
Applications in recent years have an abundance of real-time events of every kind that create a highly interactive experience for the user. However, the right tools are needed to manage these, and Reactive programming might be the answer.
To understand Reactive, both the programming model and the motivation behind it , it helps to understand the challenges that developers and companies are facing today compared to the challenges faced a decade ago. Therefore, the two major game-changers for developers and companies are:
- the huge number of concurrent users
- need for responsive applications
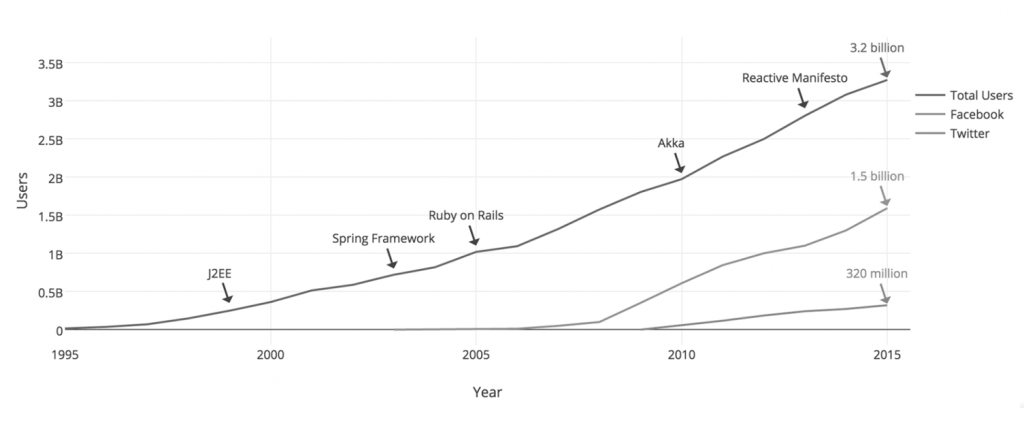
Modern applications can reach huge numbers of concurrent users, and even though the capabilities of modern hardware have continued to improve, the performance of modern software is still a key concern.
Most applications are designed around two programming models:
- Threads – coordinate state transitions as a control flow. They lean to situations where the state transitions fall into a clearly defined sequence.
- Events – are discrete, asynchronous messages, propagated around the program. There are advised when the interactions between components are more complex or unknown and the sequence of transitions is less obvious.
The fundamental problem: Blocking code
The term “non-blocking” is used in many different ways and contexts. Here we were focusing on non-blocking I/O which refers to threads not waiting for I/O operations to finish. However, sometimes people refer to APIs as non-blocking only because they do not block the current thread. But that doesn’t necessarily mean they perform non-blocking I/O.
Examples of blocking code
Take JDBC as an example. JDBC is blocking by definition. The trick here is simply to have a second thread pool that will take the JDBC requests and block instead of your main thread. Why is that helpful? It allows you to keep doing your main work, e.g. answering to HTTP requests. While your thread pool is blocked, the main thread will do the remaining work. This is nice but still blocking I/O and you will run into bottlenecks as soon as your work becomes bound by the JDBC communication.
More threads = extra memory
Consider a program that makes 100 blocking calls to a service. Each blocking call takes approximately one second to complete. In an effort to make this code concurrent and asynchronous, it uses the naive approach to spawn more thread to execute the code. We execute the requests on a fixed-sized thread-pool with 8 threads. Because of this, only 8 requests are executing simultaneously. They complete in batches, and consequently, it takes over 12 seconds to execute all 100 blocking calls
When it executes, it must block the thread that it is running on. Now you might think that you can increase the size of the thread-pool to 100 of threads and then all tasks will be executed at once and this will probably work. All of the requests are executed concurrently and all 100 complete within 1 second. This seems ideal, but, again, but still blocking code still comes at a cost.
This solution works great in the above example with only 100 blocking calls, but consider a service that must process thousands of simultaneous, blocking requests. Therefore, with 10,000 blocking requests, it’s clear that it is impossible to keep creating a new thread for each concurrent blocking call without limit:

So, to overcome this problem we use non-blocking I/O which refers to threads not waiting for I/O operations to finish.
Ways to improve performance
There are broadly two ways one can improve a program’s performance:
- Concurrency. Use more threads and more hardware resources.
- Asynchronous programming: Seek more efficiency in how current resources are used.
Concurrency.
Usually, developers write programs using blocking code. This approach is fine until there is a performance bottleneck, at which point one could think to introduce additional threads, running similar blocking code. But this scaling in resource utilization can quickly introduce complexity and concurrency problems. Worse still, blocking wastes resources. If you look closely, as soon as a program involves some latency (notably I/O, such as a database request or a network call), resources are wasted because a thread (or many threads) now sits idle, waiting for data. So the parallelization approach is not a silver bullet. It is necessary in order to access the full power of the hardware, but it is also complex to reason about and affected by resource wasting.
Asynchronous programming.
The second approach, seeking more efficiency, can be a solution to the resource-wasting problem. By writing asynchronous, non-blocking code, you let the execution switch to another active task using the same underlying resources and later come back to the current process when the asynchronous processing has finished.
Callbacks
Asynchronous methods do not have a return value. Instead, they take an extra callback parameter (a lambda or anonymous class) that gets called when the result is available. Callbacks are hard to compose together, quickly leading to code that is difficult to read and maintain (known as “Callback Hell”).
Complexity of imperative programming kills
In previous examples a common denominator was complexity. Asynchronicity, concurrency, and parallelism are very challenging characteristics to use correctly and efficiently. That is mostly because of having to think like the computer itself and imperatively define the complex interactions of state, particularly across thread and network boundaries. For instance, books like Java Concurrency in Practice by Brian Goetz and Concurrent Programming in Java by Doug Lea (Addison-Wesley) are representative of the depth, breadth, and complexity of mastering concurrency. Taking concurrency to the distributed system, and we add another layer of complexity.
Complexity kills. It sucks the life out of developers, it makes products difficult to plan, build and test, it introduces security challenges, and it causes end-user and developer frustration.
Reactive programming was designed to ease the pain of asynchronous and concurrent programming, but you must understand some core principles and semantics in order to take advantage of that. On today’s computers, everything ends up being imperative at some point as it hits the operating system and hardware. The computer must be told explicitly what needs to be done and how to do it. Humans do not think like CPUs and related systems, so we add abstractions. In conclusion, reactive-functional programming is an abstraction, just like our higher-level imperative programming idioms are abstractions for the underlying binary and assembly instructions.
Performance
Reactive and non-blocking generally do not make applications run faster. The key expected benefit of reactive and non-blocking is the ability to scale with a small number of threads and little memory. That makes applications more resilient under load because they scale in a more predictable way. However, in order to observe those benefits, you need to have some latency, something like slow and unpredictable network I/O. That is where the reactive stack begins to shine, and the differences can be dramatic.
When You Need Reactive Programming
Reactive programming might be in scenarios such as the following:
- processing user events such as mouse movement and clicks, GPS signals changing over time, touch events, and so on.
- processing any latency-bound IO events from disk or network, given that IO is inherently asynchronous
- handling data pushed at an application by a producer it cannot control
If you are handling only one event stream, classic imperative programming with a callback is going to be fine, and bringing in reactive-functional programming is not going to bring you much benefit.
If your program is like most though, and you have multiple streams and you need to combine them, have conditional logic interacting between them, and must handle failure scenarios and resource cleanup. This is where reactive-functional programming begins to shine.
The key interfaces of a reactive program
From a software design point of view, if you keep concurrency/parallelism aside to focus on software interfaces, a reactive program should have:
- an event source that implements Observable<T>
- an event sink that implements Observer<T>
- a mechanism to add subscribers to an event source
- when data appears at the source, subscribers will be notified
Observable
The Observable sequence, or simply Observable is central to the reactive pattern. An Observable represents a stream of data. Programs can be expressed largely as streams of data. Put more simply, an Observable is a sequence whose items become available over time.
Observers
The Observers, consumers of Observables, are the equivalent of listeners in the Observer pattern. When an Observer is subscribed to an Observable, it will receive the values in the sequence as they become available, without having to request them.
To support receiving events via push, an Observable/Observer pair connect via subscription.
interface Observable<T> {
Subscription subscribe(Observer s)
}Upon subscription, the Observer can have three types of events pushed to it:
- data via the onNext() function
- errors (exceptions or throwables) via the onError() function
- stream completion via the onCompleted() function
interface Observer<T> { void onNext(T t) void onError(Throwable t) void onCompleted() }
interface Observer<T> {
void onNext(T t)
void onError(Throwable t)
void onCompleted()
} The onNext() method might never be called or might be called once, many, or infinite times. The onError() and onCompleted() are terminal events, meaning that only one of them can be called only once. The observable stream finish when a terminal event is called and no further events can be sent over it. Terminal events might never occur if the stream is infinite.
Reactive programming is push-based, so the source of events (the Observable) will push new values to the consumer (the Observer). The consumer will not request the next value. In programming, push-based behavior means that the server component of an application sends updates to its clients instead of the clients having to poll the server for these updates. It’s like the saying, “Don’t call us; we’ll call you.”
Reactive Manifesto
So, what is the Reactive Manifesto? The Reactive Manifesto is a specification defining the four reactive principles. You can think of it as the map to the treasure of reactive programming, or as the bible for the programmers of the reactive programming paradigm. So, the following is the essence of four principles that Reactive Manifesto defines:
- Responsive – The system responds in a timely manner. Responsive systems focus on providing rapid and consistent response times, so they deliver a consistent quality of service.
- Resilient – In case the system faces any failure, it stays responsive. Resilience is achieved by replication, isolation, and delegation. Failures are contained within each component, isolating components from each other, so when failure has occurred in a component, it will not affect the other components or the system as a whole.
- Scalable- Reactive systems can react to changes and stay responsive under varying workload. They achieve elasticity in a cost-effective way on commodity hardware and software platforms.
- Message-driven – In order to establish the resilient principle, reactive systems need to establish a boundary between components by relying on asynchronous message passing.

Reasons to adapt functional reactive programming
So, let’s first discuss the reasons to adapt to functional reactive programming. There’s no point in changing the whole way you code unless it gets you some really significant benefits, right? Yes, functional reactive programming gets you a set of mind-blowing benefits, as listed here:
- Get rid of the callback hell: A callback is a method that gets called when a predefined event occurs. This mechanism involves a hell of a lot of code, including the interfaces, their implementations, and more. Hence, it is referred to as callback hell.
- A standard mechanism for error handling: Generally, while working with complex tasks and HTTP calls, handling errors are a major concern, especially in the absence of any standard mechanism, it becomes a headache.
- It’s a lot simpler than regular threading: Reactive programming helps to make it easier.
- A straightforward way for async operations: Threading and asynchronous operations are interrelated. As threading got easier, so did the async operations.
- One for everything, the same API for every operation: Reactive programming, offers you a simple and straightforward API. You can use it for anything and everything, be it network call, database access, computation, or UI operations.
- The functional way: Reactive programming leads you to write readable declarative code as, here, things are more functional.
- Maintainable and testable code: The most important point-by following reactive programming properly, your program becomes more maintainable and testable.
More characteristics of event-driven programming which encompasses reactive programming can be found in this article.
Conclusion
Reactive programming should be used in scenarios for which scalability and throughput are essential. Certainly, implementing systems in a reactive fashion is definitely more demanding. But the benefits are far more important, including better hardware utilization.
Bibliography:
- Tomasz Nurkiewicz, Ben Christense: Reactive Programming with RxJava, O’Reilly Media, October 2016
- https://docs.spring.io/spring/docs/current/spring-framework-reference/web-reactive.html#spring-webflux
- https://blog.codecentric.de/en/2019/04/explain-non-blocking-i-o-like-im-five/